Spotlight: A Gentle Introduction To Machine Learning Concepts In Python




Machine Learning is a branch of Artificial intelligence that deals with the study of computational algorithms and statistical models to perform tasks through patterns and interference instead of explicit tasks. The machine (Your computer) takes in the data and algorithm, learns from it, and then could use it to predict for other new instances. Machine learning is a set of tools used to build models on data that could help predict new types of the same data. Machine learning models are now very popular everywhere. You must have once wondered how Facebook knew that you know someone, or how Spotify got that really cool jam recommended to you. Well, that is machine learning and the same way Facebook could pop up someone you do not know is based on the fact that machine-learning models are not 100% accurate all the time.
Machine Learning comprises of supervised learning where we know the target or past answer and unsupervised learning where there are no targets.
In this article, we will be covering the basics of machine learning by viewing the basic ways machine learning models carry out operations to give us juicy feedback. This article is on supervised learning, as this is an introduction.
The Concepts below cover the basics of machine learning:
GROUPING DATA INTO FEATURES AND TARGETS:
As highlighted earlier, in supervised learning, we aim at predicting values based on past data (target) hence; the dataset with which we work comes with a column, which contains the values, which we are trying to predict. This is the target column. Whilst other columns, which are going to be used to predict the target are called the features. Datasets could be ambiguous, containing useless data, which we would want to get rid of, and here, data analysis and manipulation comes in handy. We would also want to have a good knowledge of the features and we can do this with a good knowledge of exploratory data analysis. Here is a link to an article on exploratory data analysis article you might find useful.
BASIC MACHINE LEARNING ALGORITHM OPERATIONS
Classification: In classification, machine learning models group data into different parts based on the algorithm provided. Popular classification algorithms include the K Nearest Neighbors, Support Vector Machines amongst others and with the help of a concept called cross-validation; we will be able to pick the best one to work with on our data. Regression: Regression algorithms operate by giving out the relationship between two or more features in our model. Examples are linear and logistic regression algorithms. Regression and classification are categorized under the same umbrella of supervised machine learning. … The main difference between them is that the output variable in regression is numerical (or continuous) while that for classification is categorical (or discrete)
THE MACHINE LEARNING WORKFLOW
Importing: By importing, we get the necessary tools we are going to be using on our machine learning model examples are the algorithms and the tools we use for exploratory data analysis
from sklearn.linearmodel import LinearRegression
Instantiating: This is the process of the creation of an instance of the machine learning method. While some of them accept parameters like the k nearest neighbours, others do not accept parameters.
my_model = LinearRegression()
Splitting into training and testing data: We split the data into training and testing sets. We go-ahead to work with the training set and then compare them with the testing set to have a glance at how well our model performed.
from sklearn.model_selection import train_test_split
X = feature columns
y = target column
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
train_test_split does a tuple unpacking of the data. The argument as seen above "test_size" is the portion of the data we are willing to allocate to the machine learning method for training.
Fit: By fitting a model, we are feeding the training set of our data to the algorithm to operate on. We could tune how the algorithm operates of the fitted data. We would fit the training data to the machine learning method.
my_model.fit(X_train, y_train)
Predict: The goal of using a machine learning algorithm is to be able to get predictions and feedbacks off of it and we do this using the predict method of the machine learning algorithm. Most machine learning algorithms are already sophisticated and ready to use so most of the work a data scientist does is with refining the data for the algorithm. We predict on the X_test from the train_test_split tuple unpacking.
prediction = my_model.predict(X_test)

EVALUATING A MODEL'S PERFORMANCE
Classification report: A classification report is a metric that gives a table of how well the algorithm performed in percentages. The table contains the precision, recall, and the f1 score. The precision column tells us the percentage score of how well the algorithm classified our model accurately. The recall column gives us feedback on how the algorithm classified data that did not belong to a category while the f1 score is a harmonic mean of the precision and recall. A classification report comes in handy for model evaluation, as it is simple to obtain.
from sklearn.metrics import classification_report
print(classification_report(y_test,predictions))
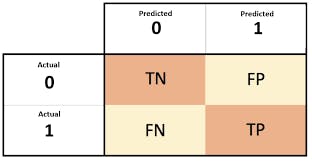
The confusion matrix: The confusion matrix method is used to summarize how the algorithm performed on our data. In a confusion matrix, the rows correspond to values the algorithm predicted while the columns correspond to the known truths (actuals). Values on the diagonal specify where the algorithm correctly classified our data while the others show where the algorithm failed. Using the confusion matrix we can compare how well different algorithms perform on our data and then go ahead to select the algorithm that best suits our data.
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test,predictions))
Cross-Validation: Cross-Validation allows us to compare different machine learning methods and get a sense of how well they will work in practice which helps us choose the machine learning algorithm that best suits our data. Cross-validation does this by splitting the data into training and testing sets. Splitting the data into n numbers, the type of cross-validation is the n cross-validation since the number of splits is arbitrary. Cross-validation uses every part of the split data to deliver.
Bias and Variance: Bias is the inability of a machine learning method to capture the true relationship between features. Variance is the difference in fits between different datasets. In machine learning, a good algorithm is one with a low bias, can accurately model the true relationship, and has low variability (it should be able to provide consistently good predictions over different datasets). When there is a case of a high bias and low variance, the model is under-fitted and when there are a low bias and a high variance, the model is over-fit. Trading bias for variance and vice-versa is a Bias Variance Trade-off.

With knowledge of these basic concepts, learning other machine learning methods would be quite easy. Follow and share this article if you find it useful. Till I get into your mind on this app next time 🐱🏍.